Apache Hadoop has gained popularity in the storage, management, and processing of large amounts of data because it can handle large volumes of highly structured data. However, Hadoop cannot handle random high-speed writing and reading and cannot change files without completely rewriting. HBase is a column-based NoSQL Hadoop database that overcomes the shortcomings of HDFS by enabling fast arbitrary writing and reading in an optimized way. In addition, relational databases with exponentially growing data cannot handle various data for better performance. HBase architecture offers scalability and separation for efficient storage and retrieval.
HBase is a data module which provides quick random access to huge amounts of data. It’s a Column Family Oriented NoSQL (Not only SQL) Database which is built on the top of the Hadoop Distributed File System and is suitable for faster reading and writing at large volumes of big data throughput with low I / O latency. Hbase is used for Performance & Scalability. HBase is known for its exceptional scalability because it can handle an increase in load and performance demands by adding various server nodes. This provides optimal performance when consistency is very important and allows developers with modern SQL systems, distributed systems.
Let’s have a look into SQL and NoSQL functionalities:
SQL: Rigid Shema, Consistency, Transactions (Scans every row)
NoSQL: Speed, Flexibility, Scaling (Go directly to Column)
Useful for bulk data
Column Oriented
Document Oriented
Key-Value Store
Graph Oriented
HBase is on Hadoop/HDFS so HDFS’s features are also applicable to HBase
Features:
- Fault tolerance
- Replication
- provides permission to Random Real-Time Access.
- High Availability
- Fast Processing
- Can access through Java API or Thrift server or REST
HBase can use on Large data volumes TB or PB, Also where we don’t need RDMS features like Transactions, Complex Queries, Complex Joins their we can use HBase.
Facebook, Adobe, Twitter, Yahoo, etc use HBase.
Data in HBase is divided under ColumnFamily, and it’s a Master-Slave architecture
Master (HMaster)
Slave (Region Server)
The sequence of process is like:

Data on the HBase table are divided into regions.
256 MB is the default size of Region and it’s configurable.
Storing data in the first Region of 256MB gets full then the next data is inserted into a new region.
Size of Regions is configurable but it’s better to keep it as 256 MB, if we change it for large files then it affects performance.
Column Family of Region contains :
- Memstore
- BlockCache
- HFile
Write Operation:
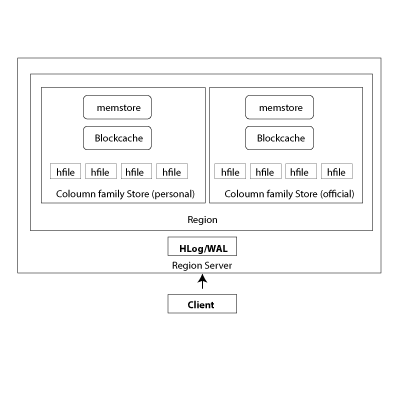
WAL: Write Ahead Log
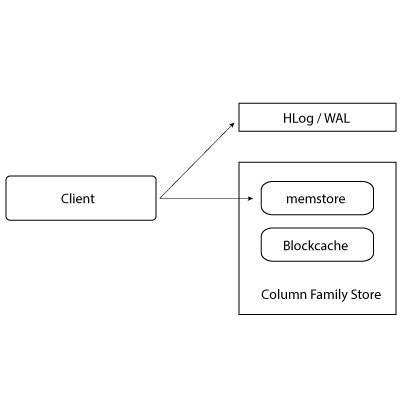
When Data gets written in HBase that’s written in Hlog i.e Write Head Log or in the Memstore.
Write Head Log is a file that maintains all Region server, means in future we lost some data in the Region server then we can pick up that data from the Write-Ahead Log.
Memstore is also called Write Buffer, The data is stored in memstore before putting data in the actual disk.
If Memstore gets full then the data gets flushed and one Hfile created
One table can contain multiple Regions
One Region server can contain multiple regions
The region contains multiple ColumnFamily Which contains 2 memories
- Read (BlockCache)
BlockCache contains the data which we frequently read, If we get request later to read that data so it can read fast, and the data which is least recently used gets clear from Block Cache because it stored in memory(RAM)
- Write (Memstore/WriteBuffer)
Memstore is also called Write Buffer, The data is stored in memstore before putting data in the actual disk.
If Memstore gets full then the data gets flushed and one Hfile created
Region server handles multiple regions
HMaster
In HBase, HMaster handles multiple Region server
Create, delete, update operation performed through HMaster
Assign Region to any region server done by HMaster
Recover and Load balancing, reassigning Regions done by HMaster
Region server manages the recovery of the failed Region server
Zookeeper
HMaster and all Region servers send heartbeat signals to Zookeeper to acknowledge that they all are active and alive. If any Region server crashes then it failed to send heartbeat and zookeeper can get to know the server failed.
In HBase
- Active HMaster (sends a heartbeat to Zookeeper)
- Inactive HMaster
If one fails another takes place on Active HMaster by zookeeper
Manages Root Metadata server
In HBase to handle Read and Write operation, there are two tables
- Root Table (Only one in the whole cluster)
- Meta table (can be more than one)
Both table handle by Zookeeper
Both tables stores on Region server, Which contains details of region server, which datastores on which region server, which region stores on which region server
When we need to read any data, then it gets ask to table that where is the data, then that table gives us the location of the region, then Memstore, BlockCache, and HFile gets read if that data find then HBase provides that data to the user
Compactions
When data write into the HBase that time data stores in HFile which has a very small size (KB)
HBase is created to update, delete data easily, If the size of that file is large then it’ll be difficult to find that file and perform the operation, so small files are quite helpful, once we find that which file contains our records then it’ll be easy to find our data.
But if the data is too large like in TB and then it’ll create lots of small files and it’ll be difficult to manage all these small files that’s why the COMPACTIONS concept is introduced in HBase
There are two types of Compactions
- Major compactions–
- If we having Region in that Column Family is stored, in that there are 4 HFiles and Combining all 4 HFiles we create 1 HFile, this task done by Admin in non-peak hours
(Combining all Hfiles of ColumnFamily into one HFile)
- Minor Compactions–
- If we having Region in that Column Family is stored, in that there are 4 HFiles and Combining 2 2 HFiles we create 2 HFiles This is the example of Minor Compaction
(Framework does the minor compaction, we don’t need to do anything, we can set criteria for Minor Compaction)
Conclusion: HBase is one of the NonSql-oriented columns that are distributed in the queue. Compared to Hadoop or Hive, HBase performs better when taking fewer notes. In this article, we look at HBase architecture and its important components.