In the data-driven economy, businesses need a streamlined, reliable way to handle and organize data, especially as data grows in volume and complexity. For many companies, managing this data for analytics, compliance, and operational efficiency is a continuous challenge.
Pioneered by Databricks and adopted by Microsoft as the cornerstone of its Fabric platform, this architecture offers a structured and scalable solution for organizing and processing vast amounts of data. Medallion Architecture provides a structured approach to data organization with layers that enhance data quality progressively.
This layered approach establishes data quality, consistency, and security, while also enabling efficient data consumption by various stakeholders, including data scientists, analysts, and business users.
Here, we explore how Medallion Architecture aligns with other data-loading techniques. Understanding how each method fits within the broader Medallion framework offers a new perspective on how data pipelines can be structured for flexibility and performance. Whether you're working with structured, semi-structured, or unstructured data, the Medallion approach offers a framework that balances efficiency with ease of data access.
The Challenge of Organizing Data
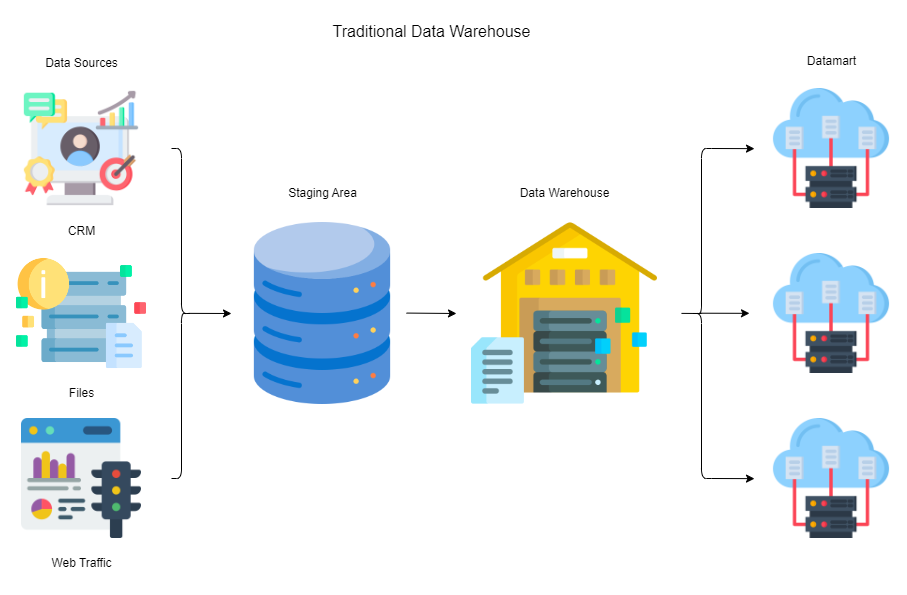
Data has become a critical asset for businesses across industries, fuelling decision-making, innovation, and customer insights. However, managing large volumes of raw data in a way that makes it accessible and useful is often challenging. To address this, companies organize data through specific structures that help sort, refine, and store information based on its purpose and usability. The traditional data warehouse includes following layers:
- Data Sources: Data comes from multiple sources like transactions, user interactions, sensors, and external providers. Netflix gathers data from user viewing habits, ratings, and searches, creating a massive pool of raw data that needs to be processed for insights into viewer preferences and content recommendations. Each source contributes different types of data, requiring companies to first organize and process this data before it becomes useful.
- Staging Area: Once data is collected, it goes to a staging area. This temporary holding space stores data without modifications, allowing it to be reviewed and transformed as necessary. A company like UPS, which processes millions of package tracking details every day, uses staging areas to initially capture data from scanners, GPS systems, and customer service logs. Here, data stays in its raw form, ready for cleaning and refinement before moving to permanent storage.
- Data Warehouse: The data warehouse is where organized, structured data resides. Here, information is cleaned, filtered, and stored in a way that allows for efficient querying and analysis. Amazon, uses data warehouses to store transaction and inventory data, facilitating powerful insights into purchasing patterns and stock levels. Unlike staging areas, data warehouses are optimized for long-term storage and fast retrieval, providing a foundation for analytics.
- Datamart: Datamarts are smaller, subject-specific databases within the broader data architecture, catering to specific business functions. Walmart uses datamarts to segment data by department (like groceries, electronics, or apparel), so each business unit has quick access to data relevant to its operations. This segmentation speeds up analysis for specific teams without overloading the main data warehouse.
Between the raw data sources and the final, analysis-ready data, many steps are involved, including operations like joins and aggregations. If you try to save the results after every transformation, you’ll likely end up with numerous intermediate files that quickly become a burden. In real-world settings, this often results in an overwhelming collection of half-processed data that becomes outdated, clogs up storage, and turns into a data swamp filled with irrelevant information that no one can use.
To manage this, a clear structure is needed to track and control the different states of data as it progresses through each transformation. Medallion Architecture offers a solution by organizing data in layers—each layer defines a stage of processing, so only valuable and relevant information is retained. This way, you’re left with a well-structured data lake, free from excess, outdated files and designed for efficient data access and analysis.
What is Medallion Architecture?
Medallion Architecture is a structured approach to data management, dividing data into three layers: bronze for raw data, silver for refined data, and gold for analytical-ready data. Each layer has a distinct role in transforming raw data into a valuable resource, moving it from raw collection to refined insight.
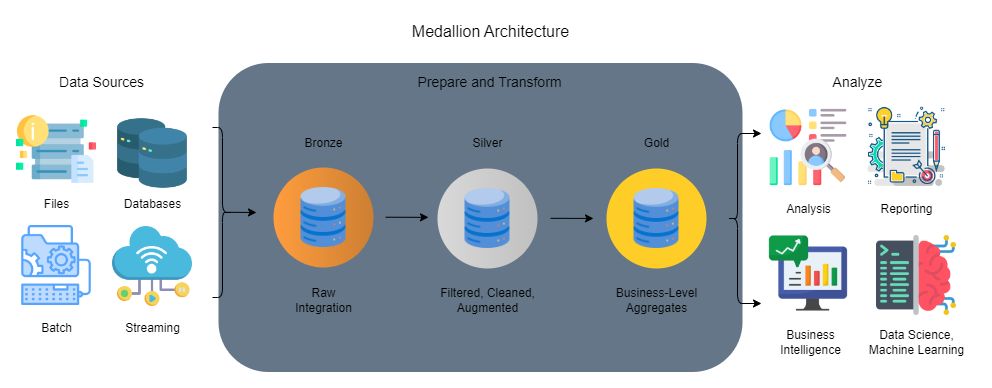
Medallion Architecture’s multi-layer design supports flexibility, enabling companies to store raw data, apply incremental transformations, and refine datasets without disrupting operations. This setup is particularly useful in industries with high data volumes and complex analysis needs, such as finance and telecommunications.
Layers in Madallion Architecture
Each layer in Medallion Architecture serves a unique function, helping to create a structured flow of data from raw inputs to actionable intelligence.
Bronze Layers
The bronze layer holds raw, unprocessed data from all sources. This includes logs, event data, and other records directly from transactional systems, sensors, and applications.
Airbnb collects vast amounts of data from its users, including search history, booking details, and user reviews. This raw data is stored in the bronze layer, preserving every detail without transformation. This is essential for cases where a full, historical view is needed, allowing Airbnb to capture unfiltered data that might later be essential for trend analysis or anomaly detection.
Silver Layers
The silver layer is where data is cleaned, transformed, and filtered. At this stage, unnecessary information is removed, and data is enriched or combined to create a more coherent picture.
A company like Spotify might process data in the silver layer by combining user listening history with demographic information, helping it to tailor music recommendations more accurately. This data is cleaner and more structured than in the bronze layer, making it easier to analyze and use in algorithms.
Gold Layers
The gold layer houses the most refined and optimized data, primed for lightning-fast analytics and insightful reporting. Here, data undergoes comprehensive transformation and aggregation, unlocking the potential for in-depth analysis.
In this layer, Coca-Cola could aggregate data on sales, customer feedback, and production efficiency, yielding insights into how promotions influence sales or how regional preferences affect product popularity. Data at this stage is prepared for dashboards, machine learning, and direct decision support.
| Layers in Madallion Architecture | |||
| Layer | Function | Use Case | Who did it? |
| Bronze | Stores raw data without transformations | Audits, error tracking | Airbnb |
| Silver | Cleans and refines data | Operational efficiency | Spotify |
| Gold | Finalized data for analysis | Forecasting, machine learning | Coca-Cola |
Advantages of Medallion Architecture
Medallion Architecture's layered approach has several advantages that help companies manage and process large amounts of data more effectively.
Improved Data Quality and Organization
By separating raw data, cleaned data, and aggregated data, Medallion Architecture reduces the clutter often found in data lakes. Retail giant Target uses a tiered approach to keep its vast pool of customer and transaction data organized. The bronze layer stores unprocessed data, while the silver and gold layers progressively refine it, improving data quality at each step.
Scalability
Medallion Architecture supports scaling as more data sources are added, making it ideal for industries with constantly increasing data volumes, like telecommunications. AT&T uses a layered architecture to store network and customer data in different stages, allowing it to scale operations smoothly and optimize data for analytics, customer insights, and network optimization.
Enhanced Performance
By separating data into layers based on processing needs, Medallion Architecture allows faster querying and more efficient data retrieval. Healthcare companies like Pfizer can optimize performance by keeping raw data (bronze) separate from refined and analysis-ready data (gold), which speeds up their research processes and supports real-time data access for clinical trials.
Disadvantages of Medallion Architecture
While Medallion Architecture offers clear benefits, it also has some limitations that need to be considered.
Increased Storage Costs
Storing data at multiple stages (bronze, silver, and gold) can significantly increase storage costs, especially for industries with high data volumes. Media-streaming services like Netflix must handle vast amounts of raw and processed data, which can become costly when data is stored across multiple layers.
Complex Data Pipeline Management
Managing multiple layers requires additional maintenance and monitoring to avoid issues like version control and data consistency. A financial institution like Goldman Sachs, which relies heavily on data accuracy for trading and risk analysis, has to allocate dedicated resources for monitoring and maintaining each layer of its data pipeline.
Processing Time Delays
Layered architectures may introduce delays, as data needs to pass through each layer before it's fully refined. In industries like e-commerce, where real-time insights are valuable, companies like Amazon sometimes face delays as raw data (bronze) moves through the silver and gold layers, which can slow down decision-making for time-sensitive analyses.
Applications and Use Cases of Medallion Architecture
Medallion Architecture is widely applicable across industries that require organized data for analytics, real-time processing, and machine learning. Here are some notable applications:
- Healthcare Analytics
Pharmaceutical companies like Moderna use layered data architectures to process clinical trial data. The bronze layer houses raw data, the silver layer refines it, and the gold layer prepares it for analysis. This setup allows for faster, more accurate insights into treatment efficacy and safety.
- Telecommunications
Telecommunications companies, such as Verizon, rely on Medallion Architecture to process data from network usage, call records, and customer interactions. By organizing raw data from millions of users in the bronze layer, refining it in the silver layer, and preparing it for analysis in the gold layer, Verizon can efficiently track and improve network performance, customer satisfaction, and fraud detection.
- Retail and Customer Insights
Retailers like Best Buy use this structure to track sales data, customer behavior, and inventory. The bronze layer collects unstructured customer transaction data, the silver layer cleans and enriches it with additional information, and the gold layer delivers customer behavior insights to improve marketing and customer service strategies.
Key Data Loading Patterns in Data Engineering
Data loading patterns are essential to how information flows through a data system. Each approach has unique characteristics suited to different needs, allowing data engineers to manage large and diverse data effectively. Here are some key data loading patterns used in modern data engineering and how they interact with Medallion Architecture.
Batch Loading
Batch loading involves moving data in groups or batches at scheduled times, like every hour or once a day. This is common in industries where immediate data processing isn't necessary. For example, Walmart uses batch loading to transfer large amounts of transactional data, such as daily sales records, to their data warehouse every night. This method is efficient for processing high volumes of data periodically and helps control system resources by avoiding continuous loading.
Stream Loading
Stream loading delivers data in real-time or near real-time, enabling applications to act quickly on new information. This pattern is widely used by Twitter, where incoming tweets and interactions are processed as they happen, allowing trends to be detected and displayed instantly. Stream loading is ideal for applications needing immediate updates, but it requires robust processing capabilities to handle continuous data flow.
Micro-Batch Processing
Micro-batch processing combines the best of batch and stream processing, offering a flexible and efficient solution. It collects data over very short intervals, such as a few seconds, and processes it in small batches. For instance, Netflix uses micro-batch processing to monitor user activity and detect potential service interruptions almost instantly. Micro-batches make it possible to react to data changes quickly without the heavy load of true streaming, making it an effective middle ground for companies requiring frequent updates without continuous processing.
Change Data Capture (CDC)
Change Data Capture (CDC) identifies and tracks changes in data over time, transferring only the updated records rather than reloading everything. This pattern is valuable for incremental updates and is commonly used in PayPal's fraud detection systems, where small, continuous updates are critical to staying on top of fraudulent activity. CDC minimizes data volume by focusing on changes, which helps keep the processing load manageable.
| Comparison of Medallion Architecture with Other Loading Patterns | |||||
| Aspects | Medallion Architecture | Batch Loading | Stream Loading | Micro-Batch Processing | Change Data Capture (CDC) |
| Data Flow | Multi-layer (bronze, silver, gold) | Periodic bulk loading | Continuous | Short interval batches | Tracks and updates changes |
| Real-Time Capability | Limited | No | Yes | Near real-time | Incremental |
| Data Volume | Reduced with layers | High | Variable | Moderate | Low |
| Benefits | Organized, structured transformation stages | Efficient for large datasets | Ideal for instant analysis | Balances real- time and batch | Minimizes redundant data |
| Challenges | Complex setup | Delayed processing | High resource requirement | May lose ultra-fine detail | Requires specific tracking setup |
| Use Case | Pfizer (clinical trial data) | Walmart (sales records) | Twitter (tweet analysis) | Netflix (service monitoring) | PayPal (fraud detection) |
Integrating Medallion Architecture with Data Loading Patterns
Medallion Architecture can be combined with batch loading, stream loading, micro-batch processing, and CDC, allowing data engineers to handle data from multiple sources in a unified system.
Using Batch Loading within Medallion Architecture
Batch loading is commonly used within Medallion’s bronze layer to initially collect large sets of raw data.
Airbnb may load historical booking data in batches to the bronze layer for long-term storage. This allows the company to hold complete, unfiltered datasets that can later be cleaned and processed without overwhelming the system.
The batch loading process aligns well with Medallion’s goal of retaining raw data that can be refined in later stages.
Implementing Stream Loading in Medallion Architecture
Stream loading is useful within the silver layer of Medallion Architecture, where real-time data requires cleaning and minimal transformation.
In an environment like Uber’s, where ride data and location information need near-instantaneous processing, stream loading is applied to capture and update the silver layer with fresh data.
This approach allows Uber to track and monitor driver and passenger locations in real-time while keeping the bronze layer separate for historical data storage.
Leveraging Micro-Batch Processing in Medallion Architecture
Micro-batch processing is effective in the silver layer as well, especially for applications needing frequent updates but not true real-time processing.
Shopify might use micro-batches to monitor transaction data, updating insights every few seconds without the heavy resources required for continuous stream loading.
The micro-batches enable Shopify to track e-commerce activity and customer behavior at frequent intervals, delivering valuable insights while minimizing resource strain.
CDC for Incremental Updates in Medallion Architecture
CDC is often used within Medallion’s gold layer, where fully refined data needs to be continuously updated.
JP Morgan Chase could use CDC to track updates in financial records, applying incremental updates to the gold layer to ensure that the most accurate and up-to-date information is available for risk analysis and regulatory reporting.
CDC helps to avoid reloading the entire dataset by capturing only the latest changes, keeping the system efficient and responsive.
Performance Optimization and Data Governance
Optimizing data performance and enforcing data governance are key to Medallion Architecture's success. Here are methods for improving data flow, scaling resources, and ensuring quality across layers.
Optimizing Data Flow Through Layers
Efficient data flow through the bronze, silver, and gold layers minimizes bottlenecks and ensures timely access to insights. Data flow optimization can include setting data retention policies, reducing unnecessary transformations, and scheduling processing tasks.
Spotify improves data flow by limiting transformations in the bronze layer, keeping raw user interaction data as unprocessed as possible. Only essential cleaning tasks (e.g., removing duplicates) are performed before data moves to the silver layer, where more intensive transformations occur. This approach allows Spotify to process millions of daily interactions efficiently, ensuring smooth flow to the analytics-ready gold layer.
Resource Allocation and Scaling
Effective resource allocation and scaling enable Medallion Architecture to handle fluctuating data loads. Companies can use auto-scaling features in cloud services or distributed processing systems to allocate resources dynamically.
Lyft, for example, uses AWS auto-scaling to manage data loads in the silver and gold layers. During peak usage, like weekends or holidays, more resources are allocated to accommodate high data flow from user activity and driver routes. This setup prevents resource bottlenecks and ensures timely insights without overcommitting resources during off-peak hours.
Data Quality and Governance at Each Layer
Medallion Architecture maintains data quality through governance policies at each layer, which helps to ensure data remains accurate, consistent, and compliant.
- Bronze Layer – Raw Data Governance
Basic quality checks prevent data corruption at this layer. LinkedIn enforces standards on incoming data streams to check for file integrity and format, discarding corrupted files before storage.
- Silver Layer – Cleaning and Transformation Governance
The silver layer introduces stricter governance, where rules for data consistency and validation are applied. FedEx uses this layer to verify the validity of logistics data, ensuring that entries meet required formats and are free from errors before moving to the gold layer.
- Gold Layer – Reporting and Compliance Governance
At this layer, data is fully refined and ready for business use, so strict governance rules ensure it complies with regulatory standards. HSBC, for example, applies compliance checks on all financial reporting data in the gold layer to meet international financial regulations.
Best Practices for Using Medallion with Other Patterns
Effectively combining Medallion Architecture with other data loading patterns requires a strategic approach that considers resource allocation, data consistency, and efficient processing. Here are the best practices.
1. Define Clear Layer Purposes and Minimize Early Transformations
Each layer in Medallion Architecture—bronze, silver, and gold—serves a specific purpose, so it's important to keep transformations to a minimum in the early layers. By storing raw data in the bronze layer, organizations can avoid unnecessary processing and ensure data remains available for future use.
Pinterest applies this principle by capturing raw user engagement data in its bronze layer without transformations. This approach enables Pinterest’s data scientists to revisit historical raw data for different analyses, from trend spotting to user behavior insights.
Transformations are only applied in the silver and gold layers, where data is refined for specific analytical use cases, maximizing efficiency.
2. Balance Real-Time and Batch Processing Needs
Balancing real-time and batch data is key to optimizing resource usage. In practice, companies often split their data loading based on urgency, processing real-time data separately from batch data.
DoorDash uses a combined approach to manage delivery data. For real-time updates, like live driver location, they use stream loading to keep data flowing directly into the silver layer, where minor adjustments make it suitable for real-time tracking. For historical records, DoorDash applies batch loading to the bronze layer, processing data in scheduled intervals.
This hybrid setup ensures that DoorDash can handle both immediate data needs and long-term storage without slowing down operations.
3. Enable Scalable Resource Allocation
Using cloud infrastructure or distributed processing enables companies to dynamically scale resources according to demand. Scaling can be especially useful for Medallion’s silver and gold layers, where complex transformations occur.
Uber implements auto-scaling on Google Cloud to allocate resources as demand changes. During peak times, like weekends or public holidays, Uber’s data processing automatically scales up to handle the increase in rider and driver data.
This scalable setup ensures that Uber's data processing runs efficiently without over-provisioning, keeping costs aligned with actual usage.
4. Regularly Cleanse and Archive Data
Avoiding data bloat is essential in Medallion Architecture. As data flows from raw to refined states, regularly archiving outdated records and removing unnecessary intermediate files prevents the system from becoming overloaded.
Slack practices regular data cleansing within its Medallion Architecture. They archive data that is over 90 days old from the bronze layer, keeping only the most recent data accessible. In the silver layer, Slack maintains an automated process to archive old chat interactions, making sure they are accessible in lower-cost storage if needed but do not take up space in high-cost, performance-optimized layers.
This prevents storage bloat and ensures high performance across Slack’s analytics.
5. Ensure Data Consistency and Validation Checks
Validation is key to maintaining reliable data through transformations. Applying consistency checks at each stage prevents errors from cascading into refined datasets, improving the quality of final reports and analytics.
Spotify applies consistency checks in the silver layer to verify that user behavior data is free from duplicates and format inconsistencies before it's aggregated for recommendations.
This step certifies that the gold layer contains only clean, validated data, making Spotify’s recommendation engine more accurate and reliable.
6. Design with Future Growth in Mind
Anticipating future data growth is critical for Medallion Architecture, where expanding volumes can affect performance. Companies benefit from periodically reassessing their data needs and planning for capacity.
Salesforce reviews its Medallion layers quarterly, projecting data growth based on usage trends. By anticipating increases in user data, Salesforce allocates additional storage and processing power in the bronze and silver layers, preventing bottlenecks as the system grows.
This foresight allows for easy implementation of new analytical tools in the gold layer, ensuring the architecture scales with evolving business needs.
7. Secure Sensitive Data with Layered Permissions
Data security is especially critical in Medallion Architecture, where different teams may need access to specific layers. By controlling permissions, companies can protect sensitive data while enabling teams to access the data they need.
Bank of America applies layered permissions across its Medallion Architecture to manage access to financial records. The bronze layer has limited access, allowing data engineers to process raw data securely, while analysts access only the gold layer, where data is fully compliant with regulations.
By segmenting permissions, Bank of America reduces exposure to sensitive information and improves compliance with data regulations.
Avoiding Common Pitfalls
Medallion Architecture, when paired with data loading patterns like batch and stream loading, needs careful implementation to avoid common pitfalls such as data redundancy, latency, and increased costs.
Avoid Over-Processing
Avoid transforming data excessively at the bronze level, which can cause data redundancy and complicate processing at later stages. Shopify focuses its transformations mainly on the silver layer, maintaining efficiency while preventing excess processing in the bronze layer.
Plan for Future Growth
Businesses should design each layer with future data scaling in mind. Pinterest manages its data layers by periodically reviewing data storage and processing capacities to anticipate growing user activity and prevent bottlenecks.
Balance Real-Time and Batch Needs
When both real-time and batch data are present, companies should choose patterns that avoid overloading layers with real-time demands. DoorDash combines batch processing for historical orders and stream processing for real-time delivery tracking, optimizing their data system’s performance.
Future Trends in Data Loading and Medallion Architecture
As data engineering advances, Medallion Architecture and loading patterns are evolving to meet new challenges and technological developments.
Automated Data Orchestration
Companies are increasingly using AI to automate data flows between layers, optimizing processes and reducing human intervention. Microsoft is developing machine learning-driven orchestration tools to move data automatically from bronze to gold, improving efficiency and reducing processing times.
Real-Time Layering Enhancements
Real-time data processing improvements will likely enhance Medallion’s adaptability, especially in industries needing instant insights. Tesla is working on real-time data updates within its architecture to process autonomous vehicle data more efficiently, enabling quicker insights for vehicle safety and AI training.
Privacy-First Data Governance
As data privacy regulations grow, future Medallion Architectures will incorporate stricter governance policies across all layers. Apple is focusing on privacy-first governance, applying encryption at each Medallion layer and anonymizing data before it reaches the gold layer to protect user data.
Conclusion
As data continues to grow in volume and complexity, the need for a structured, multi-layered system becomes even clearer. The Medallion approach isn't just about managing data—it's about transforming it into a valuable asset that supports smarter, data-driven decisions. By blending this model with traditional loading patterns, organizations can build flexible, future-ready pipelines that respond well to today's data demands.
While Medallion Architecture provides a robust foundation, its success hinges on careful considering data loading strategies. By selecting the appropriate patterns for specific use cases, organizations can optimize data pipelines, improve data quality, and enhance overall data governance.
Ready to embark on your data journey? Cloudaeon offers expert guidance and cutting-edge solutions to help you implement Medallion Architecture and optimize your data pipelines. Contact Cloudaeon today to learn more about how we can help you build a data-driven future.



